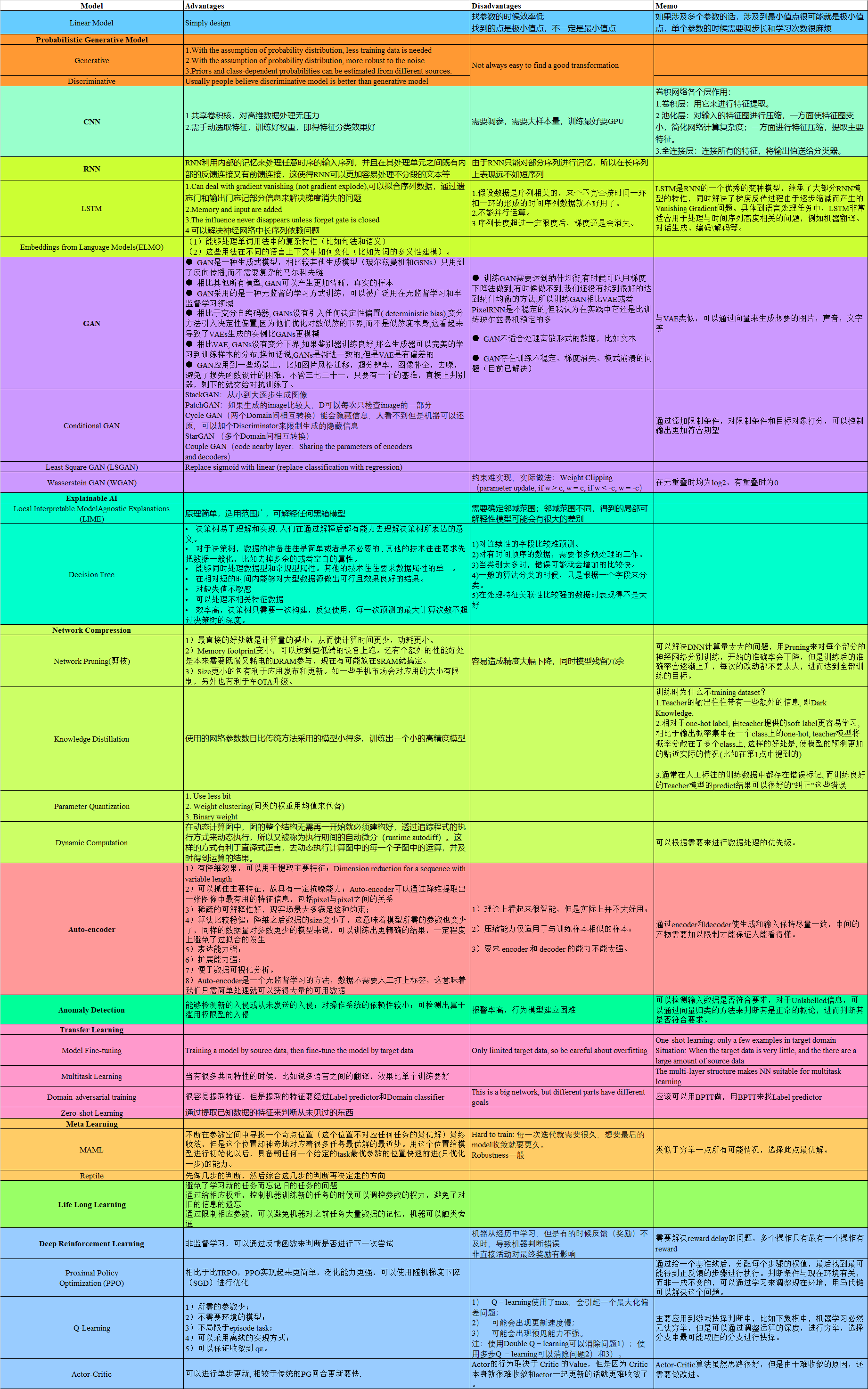
Machine Learning Model Summary
K-Means
目的
k-平均聚类的目的是:把n个点(可以是样本的一次观察或一个实例)划分到k个聚类中,使得每个点都属于离他最近的均值(此即聚类中心)对应的聚类,以之作为聚类的标准。
主成分分析(PCA)
有一些研究表明,k-均值的放松形式解(由聚类指示向量表示),可由主成分分析中的主成分给出,并且主成分分析由主方向张成的子空间与聚类图心空间是等价的。不过,主成分分析是k-均值聚类的有效放松形式并不是一个新的结果(),并且还有的研究结果直接揭示了关于“聚类图心子空间是由主成分方向张成的”这一论述的反例 。
Decision tree (决策树)
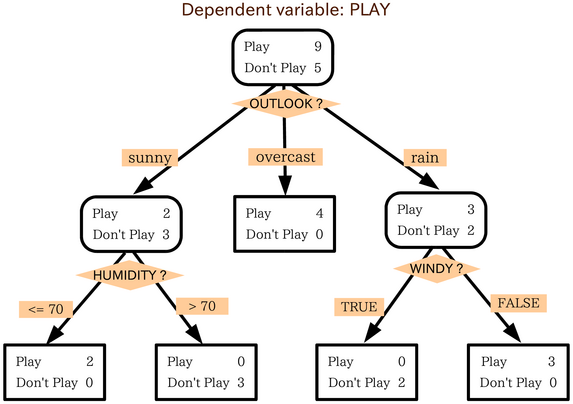
目的
数据挖掘中决策树是一种经常要用到的技术,可以用于分析数据,同样也可以用来作预测。
决策树经常在运筹学中使用,特别是在决策分析中,它帮助确定一个能最可能达到目标的策略。如果在实际中,决策不得不在没有完备知识的情况下被在线采用,一个决策树应该平行概率模型作为最佳的选择模型或在线选择模型算法。决策树的另一个使用是作为计算条件概率的描述性手段。
优点
- **决策树易于理解和实现.**人们在通过解释后都有能力去理解决策树所表达的意义。
- **对于决策树,数据的准备往往是简单或者是不必要的.**其他的技术往往要求先把数据一般化,比如去掉多余的或者空白的属性。
- 能够同时处理数据型和常规型属性。其他的技术往往要求数据属性的单一。
- 是一个白盒模型如果给定一个观察的模型,那么根据所产生的决策树很容易推出相应的逻辑表达式。
- 易于通过静态测试来对模型进行评测。表示有可能测量该模型的可信度。
- 在相对短的时间内能够对大型数据源做出可行且效果良好的结果。
缺点
对于那些各类别样本数量不一致的数据,在决策树当中信息增益的结果偏向于那些具有更多数值的特征。
Network Pruning (决策树的剪枝)
剪枝是决策树停止分支的方法之一,剪枝有分预先剪枝和后剪枝两种。预先剪枝是在树的生长过程中设定一个指标,当达到该指标时就停止生长,这样做容易产生“视界局限”,就是一旦停止分支,使得节点N成为叶节点,就断绝了其后继节点进行“好”的分支操作的任何可能性。不严格的说这会已停止的分支会误导学习算法,导致产生的树不纯度降差最大的地方过分靠近根节点。后剪枝中树首先要充分生长,直到叶节点都有最小的不纯度值为止,因而可以克服“视界局限”。然后对所有相邻的成对叶节点考虑是否消去它们,如果消去能引起令人满意的不纯度增长,那么执行消去,并令它们的公共父节点成为新的叶节点。这种“合并”叶节点的做法和节点分支的过程恰好相反,经过剪枝后叶节点常常会分布在很宽的层次上,树也变得非平衡。后剪枝技术的优点是克服了“视界局限”效应,而且无需保留部分样本用于交叉验证,所以可以充分利用全部训练集的信息。但后剪枝的计算量代价比预剪枝方法大得多,特别是在大样本集中,不过对于小样本的情况,后剪枝方法还是优于预剪枝方法的
Network Pruning优点
1)最直接的好处就是计算量的减小,从而使计算时间更少,功耗更小。
2)Memory footprint变小,可以放到更低端的设备上跑。还有个额外的性能好处是本来需要既慢又耗电的DRAM参与,现在有可能放在SRAM就搞定。
3)Size更小的包有利于应用发布和更新。如一些手机市场会对应用的大小有限制,另外也有利于车OTA升级。
Network Pruning缺点
容易造成精度大幅下降,同时模型残留冗余
Network Pruning备注
可以解决DNN计算量太大的问题,用Pruning来对每个部分的神经网络分别训练,开始的准确率会下降,但是训练后的准确率会逐渐上升,每次的改动都不要太大,进而达到全部训练的目标。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!